Recientemente, investigadores del grupo de Genética y Mejoramiento de Tomate del IICAR-CONICET y del grupo de Agro-Bioinformáticadel CIFASIS-CONICET, publicaron un artículo científico en colaboración con Investigadores de la Universidad de Georgia (USA) y del Instituto MVCRI (Bulgaria) donde presentan un innovador sistema de clasificación de la forma del fruto de tomate basado en aprendizaje automático. Este trabajo es un paso significativo hacia la modernización de la caracterización morfológica en tomate, un aspecto clave para la mejora genética y la selección de nuevas variedades.
La forma del fruto en tomate es clave para definir su calidad y valor comercial, pero actualmente la clasificación se basa en evaluaciones visuales subjetivas, lo que es muy laborioso y puede ser inconsistente. Este estudio introduce un nuevo sistema de clasificación basado en modelos de aprendizaje automático supervisados partiendo de imágenes de tomate. El flujo de trabajo del sistema estandarizado para la clasificación de la forma del fruto en tomate diseñado se muestra en la siguiente figura.
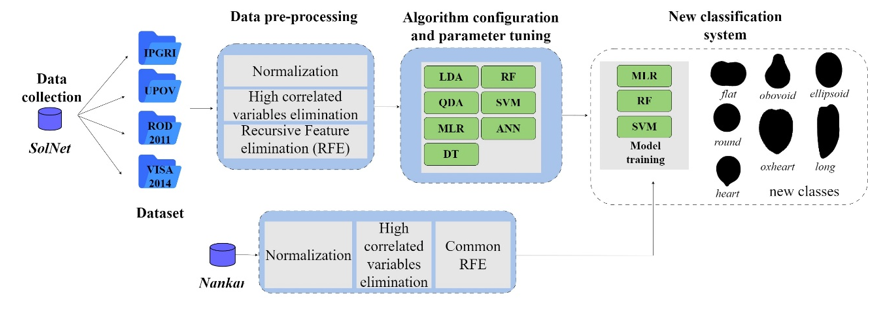
Para dicho desarrollo se utilizaron dos conjuntos de datos independientes: SolNet y Nankar. SolNet es un conjunto de datos extraído desde repositorios públicos, mientas que Nankar es producto de la investigación del grupo colaborador. La metodología desarrollada contempla los cuatro sistemas de clasificación para la forma del fruto presentes en al actualidad y siete modelos de clasificación automática como: LDA (Análisis Discriminante Lineal); QDA (Análisis Discriminante Cuadrático); MLR (Regresión Logística Multinomial); DT (Árboles De Decisión); RF (Bosque Aleatorios); SVM (Máquinas de Soporte Vectorial) y ANN (Redes Neuronales Artificiales).
Los resultados mostraron que los modelos no paramétricos como RF y SVM superaron a modelos más simples. Comparado con la clasificación visual, la clasificación automática demostró mayor precisión y consistencia. En base a métricas de clasificación, los autores propusieron un nuevo sistema de clasificación que mejoró la capacidad para capturar la variabilidad morfológica del tomate, destacándose SVM con una precisión promedio del 88%. Estos resultados subrayan el potencial del aprendizaje automático para estandarizar la clasificación de formas, reducir la subjetividad y facilitar estudios genéticos. Este trabajo no solo avanza en la comprensión de la morfología del tomate, sino que sienta las bases para futuras innovaciones en selección asistida por esta tecnología. Vazquez, D.V.; Spetale, F.E.; Nankar, A.N.; Grozeva, S.; Rodríguez, G.R. Machine Learning-Based Tomato Fruit Shape Classification System. Plants2024, 13, 2357. En este enlace puede acceder al artículo completo https://www.mdpi.com/2223-7747/13/17/2357